Every time there is a PhD defense the department sends out a notification email. These notifications come out about a week before a student’s defense, and again on the student’s defense date. While two of these additional notifications were due to my defense, and a correction about the date, I wanted to see if this was an abnormal quarter of defenses. Now that things have settled down a bit, I decided to use my email as a record of defenses between 2008 and 2014 to measure when UCSD physics graduates defend.
The code for this project is in github. This post which was generated from this notebook only contains the plotting routines. The code that I used to poll the IMAP interface of gmail, and parse/clean the data is in the gmail.ipynb notebook. I have also included some other routines found on the web, and the data output so you can play with the dataset.
1
2
3
4
5
6
7
8
9
10
# Load some libraries
import pandas as pd
import json, pickle, calendar
from datetime import datetime
from collections import Counter
from physics import COLORS,PHYS_GROUPS,get_research
# Plot routines
from matplotlib import ticker
from matplotlib.dates import date2num
from pysurvey.plot import setup, line, legend
1
2
3
4
5
# Get the saved data from gmail.ipynb
out = pickle.load(open('data/out.pickle','r'))
df = pd.read_pickle('data/dataframe.pickle')
keys = sorted(out.keys())
ndate = date2num([out[key]['date'] for key in keys])
When do physics grads graduate?
Since I am pulling this data from my email, it only covers the past six years. I think on average each physics class is roughly 30 students spanning back 8 or so years. This is as high as ~40 students entering the program each year. Some fraction of this should graduate each year assuming that there is some attrition rate, and a stable department size.
There is a much higher rate of graduation during the spring quarter, than other quarters. I am not sure why there is a significant lack of students defending in Spring of 2010. This might suggest a differences in the selection of students back in 2004, which then propegated to 2010.
Also the maximum number of defenses happened this past quarter (Spring 2014)
than in previous years. This is a ~\(2\sigma\) difference than previous spring
quarters.
I should note that I grabbed this data on June 7th, which means that some of the
other defenses happening in the next month are not included.
1
2
3
4
5
6
7
8
9
def plot_quarters():
xr = date2num([datetime(2008,6,30),
datetime(2014,6,15)])
ax = setup(figsize=(6,4), xlabel='Date', ylabel='Number of Defenses',
xr=xr, xtickv=np.linspace(min(xr), max(xr), 7))
pylab.hist(ndate,np.linspace(xr[0],xr[1],6*4+1), alpha=0.75)
ax.xaxis.set_major_formatter(ticker.FuncFormatter(lambda numdate, _: num2date(numdate).strftime('%Y-%m')))
pylab.gcf().autofmt_xdate()
plot_quarters()

Stacking this data by each year since 2008, we find the peak graduation time happens in May and June. This main peak is six times larger than the other months – roughly one student a month graduates, with six graduating at the end of the spring quarter. Additionally, there is another minor bump in September, but it is much smaller. Both bumps are probably graduates defending so that they can walk and start jobs in the fall.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def get_dayofyear():
zero = datetime(1970,1,1, hour=16)
y = np.array(keys)
z = np.zeros(len(y))
for year in range(2008,2015):
tmp = (datetime(year,1,1)-zero).total_seconds()
ii = np.where(y > tmp)
z[ii] = y[ii]-tmp
return (z-8*3600-3*24*60*60)/60.0/60.0/24.0
def plot_months():
dayofyear = get_dayofyear()
setup(figsize=(6,6),
xr=[0,365], xlabel='Day of the Year',
xtickv=np.linspace(0,365,13)-15,
xticknames=calendar.month_name[0:],
ylabel='Number of Defenses')
_ = pylab.hist(dayofyear, np.linspace(0,365,13), alpha=0.75)
pylab.gcf().autofmt_xdate()
plot_months()

We can look at this slightly differently, by dividing each month into the yearly components. It seems like in 2008, there were many defenses that happened in May, whereas in 2014, the combination of April, May, and June defenses contributed to the peak we saw in the first plot.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
def get_year():
return [out[key]['date'].year for key in keys]
def get_yearcolor(x):
return (0.1, 0.1, (x-2008)/(2015.-2008), 0.75)
def plot_months_byyear():
dayofyear = get_dayofyear()
bins = np.linspace(0,365,13)
years = get_year()
setup(figsize=(6,6),
xr=[0,365], xlabel='Day of the Year',
xtickv=np.linspace(0,365,13)-15,
xticknames=calendar.month_name[0:],
ylabel='Number of Defenses')
bottom = np.zeros(len(bins)-1)
for year in np.unique(years):
ii = np.where(years == year)[0]
v,l,_ = pylab.hist(dayofyear[ii], bins, alpha=0.75,
bottom=bottom, color=get_yearcolor(year),
label='%d'%year)
bottom += v
legend(reverse=True)
pylab.gcf().autofmt_xdate()
plot_months_byyear()

What time of the day do they graduate?
When I signed up for my defense time and date, I decided on a time to allow me to have time to fill out paperwork and have my committee in attendance. Generally this is best before the summer when people are traveling. Looking at when others graduate, they more generally choose to have their defenses in the morning ~10am, or at ~3pm.
1
2
3
4
5
6
7
8
9
10
11
12
13
def plot_hours():
hours = np.array([out[key]['date'].hour for key in keys])
setup(figsize=(6,6),
xlabel='Hour of the Day',
xtickv=np.arange(8,18,1)+0.5,
xticknames='8am,,10am,,noon,,2pm,,4pm,,6pm'.split(','),
ylabel='Fraction of Defenses')
pylab.hist(hours, np.arange(6,18,1), alpha=0.75, normed=True,
label='%d: 2008-2014 Defenses'%len(hours))
legend()
return hours
hours = plot_hours()

Also they often have their defenses on Friday. Besides the peak on Friday, the distribution is very flat, suggesting that many people choose whenever, with a minor pull towards Friday.
1
2
3
4
5
6
7
8
9
10
def plot_days():
days = (np.array(keys) - 8*3600 - 3*24*3600)%(7*24*3600)/(24*3600)
setup(xlabel='Day of the week',
xr=[0,7], xtickv=np.arange(0,7,1)+0.5,
xticknames=['Sun','Mon','Tue','Wed','Thu','Fri','Sat'],
yr=[0,0.3], ylabel='Fraction of Defenses')
pylab.hist(days, np.arange(0,7,1), normed=True, alpha=0.75)
return days
days = plot_days()

Combining this the 2D distribution is nice to look at, but lacks much significance. Fridays are dominated by Morning defenses. Mondays have a large range of afternoon defenses. The 3pm afternoon defense is pretty constant throughout the week.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def plot_week():
I = np.zeros( (7,24) )
k = 0
for i in range(7):
for j in range(24):
ii = np.where( (days==i) & (hours==j) )
I[i,j] = len(ii[0])
k += 1
ax = setup(figsize=(16,4), xlabel='Hour of the day',
xtickv=np.arange(0,25,2),
xticknames='midnight,,4am,,8am,,noon,,4pm,,8pm,,midnight'.split(','),
ytickv=np.arange(0.5,7.5,1),
yticknames=['Sunday','Monday','Tuesday','Wednesday','Thursday','Friday','Saturday'])
im = pylab.imshow(I, interpolation='nearest',
extent=(0,24,0,7),
cmap=pylab.cm.Blues)
pylab.colorbar(im, label='Number of Defenses')
plot_week()

Dependance on Subfields?
The emails also list the advisors, which allows us to determine the subfield of each defense. This is a pretty broad generalization, and may combine different subfields depending on the main advisors of each defense. However it does give us some broad generalizations of the department.
First Condensed Matter makes up the largest fraction of students graduating since 2008. This is followed by Astrophysics, and Biophysics with ~25, then High Energy with ~15 and Plasma Physics making up <5% of the department. This number depends on the number of faculy members in each field, so diving out that dependence in the second panel, we find that most subfields generate roughly two doctorates per professor in the last 6 years. This is somewhat biased as that it only includes professors who have graduated a student.
Plasma Physics seems oddly low. If we included Professor Diamond in that column, it brings it up to 1.5, however I am including him in Astophysics since he is part of CASS.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def plot_subfields():
labels, values = zip(*[[name, len(group)]
for name,group in df.sort('research_rank', ascending=False)
.groupby('research', sort=False)])
ii = np.arange(len(labels))
width = 0.9
ax = setup(figsize=(14,6), subplt=(1,2,1),
ylabel='Defenses')
barlist = pylab.bar(ii,values,width, alpha=0.7)
for label,bar in zip(labels,barlist):
bar.set_color(COLORS.get(label))
l, lab = pylab.xticks(ii+width*0.5, labels);
pylab.setp(lab, rotation=90);
ax2 = ax.twinx()
ax2.axes.set_ylim(0, ax.axes.get_ylim()[1]/np.sum(values))
ax2.yaxis.set_label_text('Fraction of All Graduates')
labels, values = zip(*Counter({name:len(group)/float(len(np.unique(group.advisor)))
for name,group in df.groupby('research')}).most_common())
ax = setup(subplt=(1,2,2), ylabel='Defenses / Professor')
barlist = pylab.bar(ii,values,width, alpha=0.7)
for label,bar in zip(labels,barlist):
bar.set_color(COLORS.get(label))
l, lab = pylab.xticks(ii+width*0.5, labels);
pylab.setp(lab, rotation=90)
setup(wspace=0.3)
plot_subfields()

There seems to be no significant trends for any of the subfields by year. Genereally there are ~19 students who graduate each year. Meaning that roughly 19/30=~63% of students who enter go on to defend their thesis. This does not control for differences in masters students, or foriegn students since they are likely prescreened for the qualification exam.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def get_topics():
return [out[key]['research'] for key in keys]
def plot_years_bysubfield():
ndate = np.array(date2num([out[key]['date'] for key in keys]))
topics = np.array(get_topics())
xr = date2num([datetime(2009,1,1),
datetime(2015,1,1)])
ax = setup(figsize=(6,6),
xlabel='Date', ylabel='Number of Defenses',
xr=xr, xtickv=np.linspace(min(xr), max(xr), 7),
yr=[0,30])
bins = np.linspace(xr[0],xr[1],6+1)
bottom = np.zeros(len(bins)-1)
for topic in ['Condensed Matter','Astrophysics','Biophysics','High Energy', 'Plasma Physics']:
ii = np.where(topics == topic)[0]
v,l,_ = pylab.hist(ndate[ii], bins, alpha=0.75, bottom=bottom,
label=topic, color=COLORS.get(topic))
bottom += v
legend(loc=2)
ax.xaxis.set_major_formatter(ticker.FuncFormatter(lambda numdate, _: num2date(numdate).strftime('%Y-%m')))
pylab.gcf().autofmt_xdate()
plot_years_bysubfield()

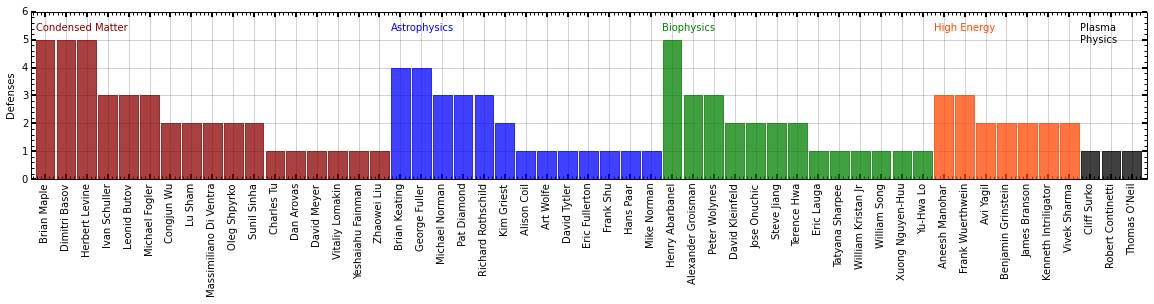
Breaking this up by subfield, these numbers are dominated by a few groups pumping out many (four to five) students, and a tail of professors that have graduated a single student. This does not seem to strongly depend on the tenure age of the professor, generally there is a slight trend where older more established groups have more students defending. Mainly this trend appears to be one dominated by experiment vs. theory, with large experiment labs having many more students.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
def add_titles(labels, barlist):
tmp = ''
for label, bar in zip(labels,barlist):
research = get_research(label)
color = COLORS.get(research)
bar.set_color(color)
if research != tmp:
lab = research.replace(' ','\n') if ('Plasma' in research) else research
pylab.text(bar.get_x(), 5.6, lab, color=color,
va='top')
tmp = research
def plot_advisors():
groups = (df.sort(['research_rank','advisor_rank','advisor'],
ascending=[0,0,1])
.groupby('advisor',sort=False))
labels, values = zip(*[[name,len(group)] for name,group in groups])
ii = np.arange(len(labels))
width = 0.9
setup(figsize=(20,3),
xr=[-0.2,len(ii)+0.2],
yr=[0,max(values)+1], ylabel='Defenses')
barlist = pylab.bar(ii,values,width, alpha=0.75)
add_titles(labels, barlist)
l, lab = pylab.xticks(ii+width*0.5, labels)
pylab.setp(lab, rotation=90)
plot_advisors()

Larger version of this figure can be found here.
{kind=link}
Gender
The emails list each student with either an “Mr” or “Ms” which we can use to construct a comparison of gender.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
def plot_gender():
xr = date2num([datetime(2008,6,30),
datetime(2014,6,15)])
gender = np.array([out[key]['gender'] for key in keys])
ax = setup(figsize=(12,6), subplt=(1,2,1),
xr=xr, xtickv=np.linspace(xr[0]+1, xr[1], 7),
yr=[0,19], ylabel='Number of Defenses')
bins = np.linspace(xr[0], xr[1], 6*2+1)
bottom = np.zeros(len(bins)-1)
for gen in ['male','female']:
ii = np.where(gender == gen)[0]
v,l,_ = hist(ndate[ii], bins, alpha=0.75, label=gen, bottom=bottom)
bottom += v
legend(loc=2, reverse=True)
ax.xaxis.set_major_formatter(ticker.FuncFormatter(lambda numdate, _: num2date(numdate).strftime('%Y-%m')))
pylab.gcf().autofmt_xdate()
ax = setup(subplt=(1,2,2),
xr=xr, xtickv=np.linspace(xr[0]+1, xr[1], 7),
yr=[0,0.6], ylabel='Fraction of Female Defenses')
fv,fl = np.histogram(ndate[gender == 'female'], bins)
mv,ml = np.histogram(ndate[gender == 'male'], bins)
# pylab.bar(ml[:-1], fv/(1.*mv +fv), width=np.diff(ml)*0.9)
e = 1.0*fv/(mv +fv)
pylab.errorbar(ml[:-1]+np.diff(ml[:2])/2.0, e,
np.sqrt(e*(1-e)/(mv+fv)),
fmt='sk', lw=2)
ax.xaxis.set_major_formatter(ticker.FuncFormatter(lambda numdate, _: num2date(numdate).strftime('%Y-%m')))
pylab.gcf().autofmt_xdate()
setup(wspace=0.2)
e = 20/(87+20.)
print 'Fraction of female defenses: %4.2f +\- %4.2f'%(e, np.sqrt(e*(1-e)/87.0))
plot_gender()
Fraction of female defenses: 0.19 +\- 0.04
I am not sure what useful comparisons can be made from this data set. The fraction of defenses is higher, but well within the fraction for classes between 2002 and 2008. There are more female graduates after 2011 than before which is a good sign. There may be some trends with sub field, but larger data sets (combinations with other similarly ranked schools) would be needed to make any statements.
1
2
3
4
5
6
7
print 'Comparison of subfields'
print ' Subfield N Frac Err'
print '-'*31
for name, group in df.groupby('research'):
female = len(np.where(group.gender == 'female')[0])
frac = female/float(len(group))
print '%18s % 1d %4.2f %4.2f'%(name, female, frac, np.sqrt(frac*(1-frac)/float(len(group))))
Comparison of subfields
Subfield N Frac Err
-------------------------------
Astrophysics 6 0.23 0.08
Biophysics 5 0.20 0.08
Condensed Matter 7 0.17 0.06
High Energy 2 0.12 0.08
Plasma Physics 0 0.00 0.00